

We've all been there, the final rush, sprint ending, lots of stuff that needs to be done but there's not enough time. The clock is ticking and we'll barely make it to the finish line. It's time to start making sacrifices.
Let the chess game begin
Programming is kind of like a game of chess. You have to protect the most important pieces: your code deliverables. So as in a game of chess, the first sacrifice is your pawns. Sure, they play an important role on the board, but come on, you need to keep the King safe and win the game!
Time is running out, time to sacrifice the pawns or lose the king. Who is your weakest pawn? Documentation of course! Yes, it is good to document the API so whoever comes next understands exactly what to expect and what it needs, but come on, time's up, and the specs are in a Jira ticket, Google Doc or someplace where we already defined the requirements and kind of wrote some sample Json of how it is gonna be right? That should be enough for the time being right? If anyone has any doubts or questions, he/she can just ping me, no worries!
Now, if we somehow manage not to sacrifice the pawn, something as awful is going to happen to it. It is going to move around in the board and then find itself in front of an enemy piece and get stuck. Want to know who is that enemy piece? Yup, you got it: Tech Debt.
Making sacrifices
So your pawn is stuck there until you or your team somehow move enough enemy pieces to clear the way and let the pawn move again. But unfortunately you are moving your pieces by order of priority because you ran out of time and documentation was not the only thing you sacrificed.
As the deadline looms close to the horizon, the next thing you sacrifice is of course code coverage to that dreaded enemy piece called Tech Debt. And unlike documentation, this one tends to bite you back faster, so you have to deal with it first.
And now we are in a vicious cycle where documentation for this incredibly complex Swiss pocket watch we've built resides in this ever fading cache of ours called short term memory, being quickly replaced by the ever growing complexity of this genuine work of art we constantly release because we develop in AGILE. A couple of sprints later, you can't even recall what is that spark plug doing in a Swiss watch! You must have put it there for a reason right? Oh well, you'll figure it out later. That's what tech debt is for.
Oh, did I forget to mention all the sprint time we have to devote to knowledge transfer the following sprints for the people who'll be using the API?
The real cost of sacrificing the pawn
So why is it we need to sacrifice documentation for the common good of delivering on time? Is it because it is hard? No! There are plenty of tools out there that make it easy for us, like Swagger or Apiary.
Is it because it is time consuming? Yes! I believe that's the reason. We need to write a whole file or manifest where we explain to these tools what our API does so they translate it to documentation.
The worst part is, this is out of our application code, so we loose track of what we are doing to write this explanation and this slows down our process. That's why it is the first piece in the board we sacrifice! Because it slows us down.
The thing with the pawn in a game of chess is, even though at the beginning it looks like an expendable piece, let's not forget that if we take that pawn all the way to the end, to the other side of the board, once it reaches that end, it can become the most powerful piece in all the board: the Queen.
Imagine how much trouble we can prevent, how much time we can save, if we have a fully documented API.
But how do we do it? Easy! We make it part of the code.
I'm going to show you how simply it is done in the Hapi framework for NodeJS.
Making documentation part of the code
Hapi is a pretty amazing framework developed by Walmart labs. It follows a configuration first approach. Because of this, it is simple to document the API within the code, in Swagger, using a plugin called hapi-swagger and Joi.
Joi is a schema definition and validation library for Hapi. Basically we can define and describe a schema of an object, and whenever we get that in the payload, we can validate it. The beauty of this is that we can fully describe the schema and its properties.
So then comes hapi-swagger, which basically takes these schemas defined by Joi, within the code, and then automatically builds the API documentation for us using the schemas we provide. We simply tell it what schema it should receive, and what we will reply according to different scenarios (success, authentication failure, errors, etc.).
Let me show you how we build a schema with Joi:
As you can see, when we define the schema we can provide values like description, example, and label, which hapi-swagger picks up and builds the documentation on. It does not slow us down, and better yet, it forces best practice on us!
So schema is the first part. We have fully documented objects. Now we need to document the actions. With Hapi we do it in the routes, which is where we write controller logic (or the handler, as is known in Hapi).
As you can see, there is a lot of documentation in our code explaining what the route does, what it expects as payload, and what it will return.
You can see we describe the route, we describe the different responses we give, and the object each one will return, which we defined in our schema.
At the bottom we validate the payload against our User schema and we check that the authentication headers are sent. The results? See for yourself:
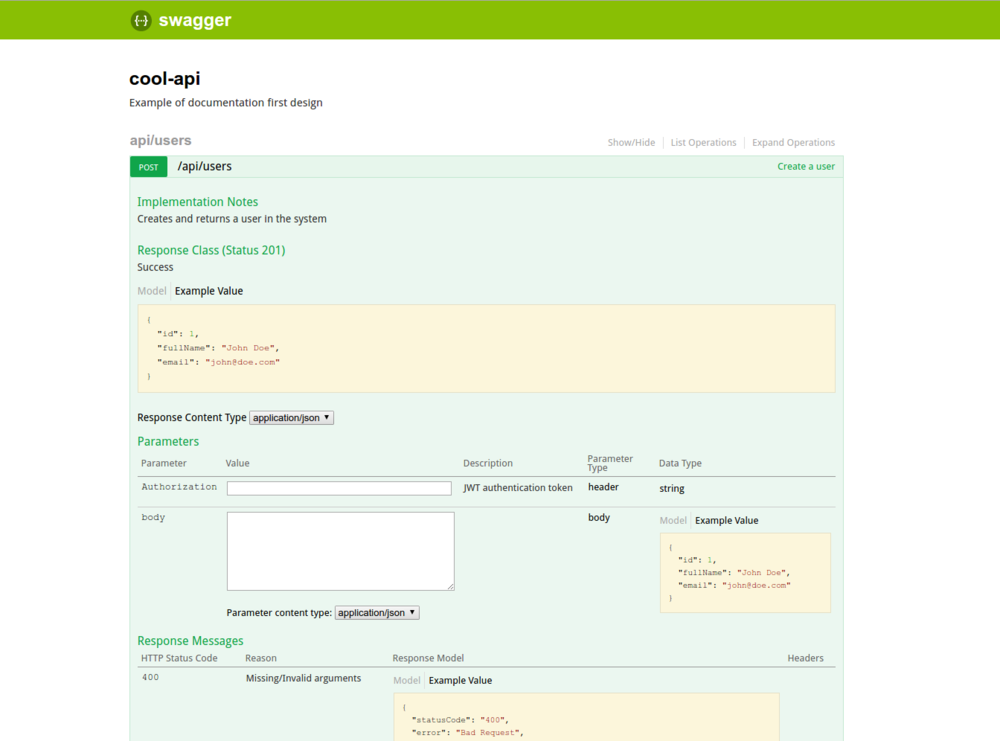
And since this is Swagger, this is actually a working client with which we can test our API, live, not just some dummy values!
Of course there's more code to this, but it is mainly boilerplate code, and out of the scope for this post (you can check some sample code here).
The best thing is, even though we haven't even laid a single line of controller code, we already have our specs defined. If our schema or specs change, once we update the code, the documentation automatically updates so it never slows us down. It actually saves us time!
And that my friend is how the Pawn became the Queen!